> For the complete documentation index, see [llms.txt](https://boinc-ai.gitbook.io/transformers/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://boinc-ai.gitbook.io/transformers/api/models/vision-models/nat.md).
# NAT
## Neighborhood Attention Transformer
### Overview
NAT was proposed in [Neighborhood Attention Transformer](https://arxiv.org/abs/2204.07143) by Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi.
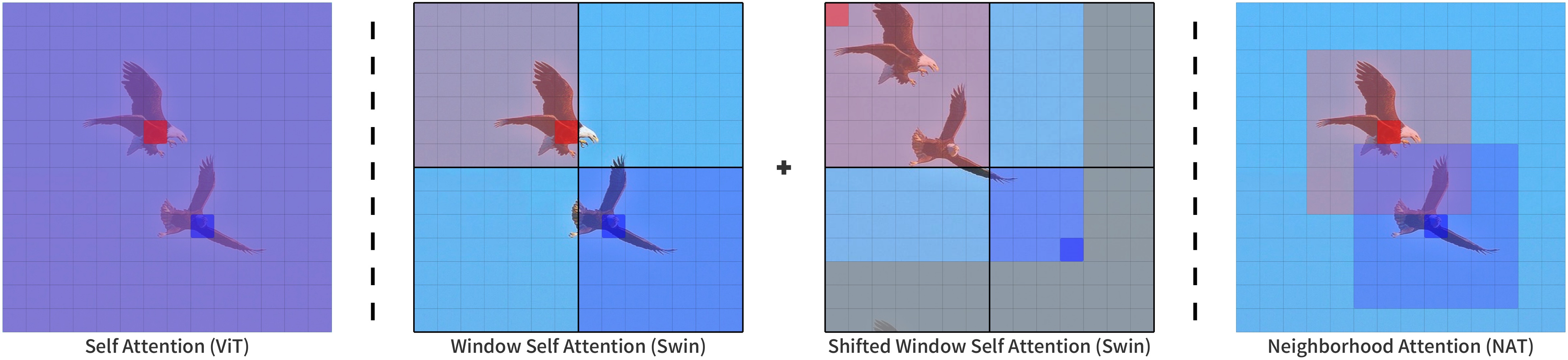
It is a hierarchical vision transformer based on Neighborhood Attention, a sliding-window self attention pattern.
The abstract from the paper is the following:
*We present Neighborhood Attention (NA), the first efficient and scalable sliding-window attention mechanism for vision. NA is a pixel-wise operation, localizing self attention (SA) to the nearest neighboring pixels, and therefore enjoys a linear time and space complexity compared to the quadratic complexity of SA. The sliding-window pattern allows NA’s receptive field to grow without needing extra pixel shifts, and preserves translational equivariance, unlike Swin Transformer’s Window Self Attention (WSA). We develop NATTEN (Neighborhood Attention Extension), a Python package with efficient C++ and CUDA kernels, which allows NA to run up to 40% faster than Swin’s WSA while using up to 25% less memory. We further present Neighborhood Attention Transformer (NAT), a new hierarchical transformer design based on NA that boosts image classification and downstream vision performance. Experimental results on NAT are competitive; NAT-Tiny reaches 83.2% top-1 accuracy on ImageNet, 51.4% mAP on MS-COCO and 48.4% mIoU on ADE20K, which is 1.9% ImageNet accuracy, 1.0% COCO mAP, and 2.6% ADE20K mIoU improvement over a Swin model with similar size.*
Tips:
* One can use the [AutoImageProcessor](https://huggingface.co/docs/transformers/v4.34.1/en/model_doc/auto#transformers.AutoImageProcessor) API to prepare images for the model.
* NAT can be used as a *backbone*. When `output_hidden_states = True`, it will output both `hidden_states` and `reshaped_hidden_states`. The `reshaped_hidden_states` have a shape of `(batch, num_channels, height, width)` rather than `(batch_size, height, width, num_channels)`.
Notes:
* NAT depends on [NATTEN](https://github.com/SHI-Labs/NATTEN/)’s implementation of Neighborhood Attention. You can install it with pre-built wheels for Linux by referring to [shi-labs.com/natten](https://shi-labs.com/natten), or build on your system by running `pip install natten`. Note that the latter will likely take time to compile. NATTEN does not support Windows devices yet.
* Patch size of 4 is only supported at the moment.
Neighborhood Attention compared to other attention patterns. Taken from the [original paper](https://arxiv.org/abs/2204.07143).
This model was contributed by [Ali Hassani](https://huggingface.co/alihassanijr). The original code can be found [here](https://github.com/SHI-Labs/Neighborhood-Attention-Transformer).
### Resources
A list of official BOINC AI and community (indicated by 🌎) resources to help you get started with NAT.
Image Classification
* [NatForImageClassification](https://huggingface.co/docs/transformers/v4.34.1/en/model_doc/nat#transformers.NatForImageClassification) is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
* See also: [Image classification task guide](https://huggingface.co/docs/transformers/tasks/image_classification)
If you’re interested in submitting a resource to be included here, please feel free to open a Pull Request and we’ll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
### NatConfig
#### class transformers.NatConfig
[\](https://github.com/huggingface/transformers/blob/v4.34.1/src/transformers/models/nat/configuration_nat.py#L30)
( patch\_size = 4num\_channels = 3embed\_dim = 64depths = \[3, 4, 6, 5]num\_heads = \[2, 4, 8, 16]kernel\_size = 7mlp\_ratio = 3.0qkv\_bias = Truehidden\_dropout\_prob = 0.0attention\_probs\_dropout\_prob = 0.0drop\_path\_rate = 0.1hidden\_act = 'gelu'initializer\_range = 0.02layer\_norm\_eps = 1e-05layer\_scale\_init\_value = 0.0out\_features = Noneout\_indices = None\*\*kwargs )
Parameters
* **patch\_size** (`int`, *optional*, defaults to 4) — The size (resolution) of each patch. NOTE: Only patch size of 4 is supported at the moment.
* **num\_channels** (`int`, *optional*, defaults to 3) — The number of input channels.
* **embed\_dim** (`int`, *optional*, defaults to 64) — Dimensionality of patch embedding.
* **depths** (`List[int]`, *optional*, defaults to `[2, 2, 6, 2]`) — Number of layers in each level of the encoder.
* **num\_heads** (`List[int]`, *optional*, defaults to `[3, 6, 12, 24]`) — Number of attention heads in each layer of the Transformer encoder.
* **kernel\_size** (`int`, *optional*, defaults to 7) — Neighborhood Attention kernel size.
* **mlp\_ratio** (`float`, *optional*, defaults to 3.0) — Ratio of MLP hidden dimensionality to embedding dimensionality.
* **qkv\_bias** (`bool`, *optional*, defaults to `True`) — Whether or not a learnable bias should be added to the queries, keys and values.
* **hidden\_dropout\_prob** (`float`, *optional*, defaults to 0.0) — The dropout probability for all fully connected layers in the embeddings and encoder.
* **attention\_probs\_dropout\_prob** (`float`, *optional*, defaults to 0.0) — The dropout ratio for the attention probabilities.
* **drop\_path\_rate** (`float`, *optional*, defaults to 0.1) — Stochastic depth rate.
* **hidden\_act** (`str` or `function`, *optional*, defaults to `"gelu"`) — The non-linear activation function (function or string) in the encoder. If string, `"gelu"`, `"relu"`, `"selu"` and `"gelu_new"` are supported.
* **initializer\_range** (`float`, *optional*, defaults to 0.02) — The standard deviation of the truncated\_normal\_initializer for initializing all weight matrices.
* **layer\_norm\_eps** (`float`, *optional*, defaults to 1e-12) — The epsilon used by the layer normalization layers.
* **layer\_scale\_init\_value** (`float`, *optional*, defaults to 0.0) — The initial value for the layer scale. Disabled if <=0.
* **out\_features** (`List[str]`, *optional*) — If used as backbone, list of features to output. Can be any of `"stem"`, `"stage1"`, `"stage2"`, etc. (depending on how many stages the model has). If unset and `out_indices` is set, will default to the corresponding stages. If unset and `out_indices` is unset, will default to the last stage.
* **out\_indices** (`List[int]`, *optional*) — If used as backbone, list of indices of features to output. Can be any of 0, 1, 2, etc. (depending on how many stages the model has). If unset and `out_features` is set, will default to the corresponding stages. If unset and `out_features` is unset, will default to the last stage.
This is the configuration class to store the configuration of a [NatModel](https://huggingface.co/docs/transformers/v4.34.1/en/model_doc/nat#transformers.NatModel). It is used to instantiate a Nat model according to the specified arguments, defining the model architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of the Nat [shi-labs/nat-mini-in1k-224](https://huggingface.co/shi-labs/nat-mini-in1k-224) architecture.
Configuration objects inherit from [PretrainedConfig](https://huggingface.co/docs/transformers/v4.34.1/en/main_classes/configuration#transformers.PretrainedConfig) and can be used to control the model outputs. Read the documentation from [PretrainedConfig](https://huggingface.co/docs/transformers/v4.34.1/en/main_classes/configuration#transformers.PretrainedConfig) for more information.
Example:
Copied
```
>>> from transformers import NatConfig, NatModel
>>> # Initializing a Nat shi-labs/nat-mini-in1k-224 style configuration
>>> configuration = NatConfig()
>>> # Initializing a model (with random weights) from the shi-labs/nat-mini-in1k-224 style configuration
>>> model = NatModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
```
### NatModel
#### class transformers.NatModel
[\](https://github.com/huggingface/transformers/blob/v4.34.1/src/transformers/models/nat/modeling_nat.py#L678)
( configadd\_pooling\_layer = True )
Parameters
* **config** ([NatConfig](https://huggingface.co/docs/transformers/v4.34.1/en/model_doc/nat#transformers.NatConfig)) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the [from\_pretrained()](https://huggingface.co/docs/transformers/v4.34.1/en/main_classes/model#transformers.PreTrainedModel.from_pretrained) method to load the model weights.
The bare Nat Model transformer outputting raw hidden-states without any specific head on top. This model is a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) sub-class. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
**forward**
[\](https://github.com/huggingface/transformers/blob/v4.34.1/src/transformers/models/nat/modeling_nat.py#L708)
( pixel\_values: typing.Optional\[torch.FloatTensor] = Noneoutput\_attentions: typing.Optional\[bool] = Noneoutput\_hidden\_states: typing.Optional\[bool] = Nonereturn\_dict: typing.Optional\[bool] = None ) → `transformers.models.nat.modeling_nat.NatModelOutput` or `tuple(torch.FloatTensor)`
Parameters
* **pixel\_values** (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`) — Pixel values. Pixel values can be obtained using [AutoImageProcessor](https://huggingface.co/docs/transformers/v4.34.1/en/model_doc/auto#transformers.AutoImageProcessor). See [ViTImageProcessor.**call**()](https://huggingface.co/docs/transformers/v4.34.1/en/model_doc/deit#transformers.DeiTFeatureExtractor.__call__) for details.
* **output\_attentions** (`bool`, *optional*) — Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned tensors for more detail.
* **output\_hidden\_states** (`bool`, *optional*) — Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for more detail.
* **return\_dict** (`bool`, *optional*) — Whether or not to return a [ModelOutput](https://huggingface.co/docs/transformers/v4.34.1/en/main_classes/output#transformers.utils.ModelOutput) instead of a plain tuple.
Returns
`transformers.models.nat.modeling_nat.NatModelOutput` or `tuple(torch.FloatTensor)`
A `transformers.models.nat.modeling_nat.NatModelOutput` or a tuple of `torch.FloatTensor` (if `return_dict=False` is passed or when `config.return_dict=False`) comprising various elements depending on the configuration ([NatConfig](https://huggingface.co/docs/transformers/v4.34.1/en/model_doc/nat#transformers.NatConfig)) and inputs.
* **last\_hidden\_state** (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`) — Sequence of hidden-states at the output of the last layer of the model.
* **pooler\_output** (`torch.FloatTensor` of shape `(batch_size, hidden_size)`, *optional*, returned when `add_pooling_layer=True` is passed) — Average pooling of the last layer hidden-state.
* **hidden\_states** (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`) — Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each stage) of shape `(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
* **attentions** (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`) — Tuple of `torch.FloatTensor` (one for each stage) of shape `(batch_size, num_heads, sequence_length, sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
* **reshaped\_hidden\_states** (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`) — Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each stage) of shape `(batch_size, hidden_size, height, width)`.
Hidden-states of the model at the output of each layer plus the initial embedding outputs reshaped to include the spatial dimensions.
The [NatModel](https://huggingface.co/docs/transformers/v4.34.1/en/model_doc/nat#transformers.NatModel) forward method, overrides the `__call__` special method.
Although the recipe for forward pass needs to be defined within this function, one should call the `Module` instance afterwards instead of this since the former takes care of running the pre and post processing steps while the latter silently ignores them.
Example:
Copied
```
>>> from transformers import AutoImageProcessor, NatModel
>>> import torch
>>> from datasets import load_dataset
>>> dataset = load_dataset("boincai/cats-image")
>>> image = dataset["test"]["image"][0]
>>> image_processor = AutoImageProcessor.from_pretrained("shi-labs/nat-mini-in1k-224")
>>> model = NatModel.from_pretrained("shi-labs/nat-mini-in1k-224")
>>> inputs = image_processor(image, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
>>> list(last_hidden_states.shape)
[1, 7, 7, 512]
```
### NatForImageClassification
#### class transformers.NatForImageClassification
[\](https://github.com/huggingface/transformers/blob/v4.34.1/src/transformers/models/nat/modeling_nat.py#L770)
( config )
Parameters
* **config** ([NatConfig](https://huggingface.co/docs/transformers/v4.34.1/en/model_doc/nat#transformers.NatConfig)) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the [from\_pretrained()](https://huggingface.co/docs/transformers/v4.34.1/en/main_classes/model#transformers.PreTrainedModel.from_pretrained) method to load the model weights.
Nat Model transformer with an image classification head on top (a linear layer on top of the final hidden state of the \[CLS] token) e.g. for ImageNet.
This model is a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) sub-class. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
**forward**
[\](https://github.com/huggingface/transformers/blob/v4.34.1/src/transformers/models/nat/modeling_nat.py#L787)
( pixel\_values: typing.Optional\[torch.FloatTensor] = Nonelabels: typing.Optional\[torch.LongTensor] = Noneoutput\_attentions: typing.Optional\[bool] = Noneoutput\_hidden\_states: typing.Optional\[bool] = Nonereturn\_dict: typing.Optional\[bool] = None ) → `transformers.models.nat.modeling_nat.NatImageClassifierOutput` or `tuple(torch.FloatTensor)`
Parameters
* **pixel\_values** (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`) — Pixel values. Pixel values can be obtained using [AutoImageProcessor](https://huggingface.co/docs/transformers/v4.34.1/en/model_doc/auto#transformers.AutoImageProcessor). See [ViTImageProcessor.**call**()](https://huggingface.co/docs/transformers/v4.34.1/en/model_doc/deit#transformers.DeiTFeatureExtractor.__call__) for details.
* **output\_attentions** (`bool`, *optional*) — Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned tensors for more detail.
* **output\_hidden\_states** (`bool`, *optional*) — Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for more detail.
* **return\_dict** (`bool`, *optional*) — Whether or not to return a [ModelOutput](https://huggingface.co/docs/transformers/v4.34.1/en/main_classes/output#transformers.utils.ModelOutput) instead of a plain tuple.
* **labels** (`torch.LongTensor` of shape `(batch_size,)`, *optional*) — Labels for computing the image classification/regression loss. Indices should be in `[0, ..., config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
Returns
`transformers.models.nat.modeling_nat.NatImageClassifierOutput` or `tuple(torch.FloatTensor)`
A `transformers.models.nat.modeling_nat.NatImageClassifierOutput` or a tuple of `torch.FloatTensor` (if `return_dict=False` is passed or when `config.return_dict=False`) comprising various elements depending on the configuration ([NatConfig](https://huggingface.co/docs/transformers/v4.34.1/en/model_doc/nat#transformers.NatConfig)) and inputs.
* **loss** (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided) — Classification (or regression if config.num\_labels==1) loss.
* **logits** (`torch.FloatTensor` of shape `(batch_size, config.num_labels)`) — Classification (or regression if config.num\_labels==1) scores (before SoftMax).
* **hidden\_states** (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`) — Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each stage) of shape `(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
* **attentions** (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`) — Tuple of `torch.FloatTensor` (one for each stage) of shape `(batch_size, num_heads, sequence_length, sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
* **reshaped\_hidden\_states** (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`) — Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each stage) of shape `(batch_size, hidden_size, height, width)`.
Hidden-states of the model at the output of each layer plus the initial embedding outputs reshaped to include the spatial dimensions.
The [NatForImageClassification](https://huggingface.co/docs/transformers/v4.34.1/en/model_doc/nat#transformers.NatForImageClassification) forward method, overrides the `__call__` special method.
Although the recipe for forward pass needs to be defined within this function, one should call the `Module` instance afterwards instead of this since the former takes care of running the pre and post processing steps while the latter silently ignores them.
Example:
Copied
```
>>> from transformers import AutoImageProcessor, NatForImageClassification
>>> import torch
>>> from datasets import load_dataset
>>> dataset = load_dataset("boincai/cats-image")
>>> image = dataset["test"]["image"][0]
>>> image_processor = AutoImageProcessor.from_pretrained("shi-labs/nat-mini-in1k-224")
>>> model = NatForImageClassification.from_pretrained("shi-labs/nat-mini-in1k-224")
>>> inputs = image_processor(image, return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> # model predicts one of the 1000 ImageNet classes
>>> predicted_label = logits.argmax(-1).item()
>>> print(model.config.id2label[predicted_label])
tiger cat
```