> For the complete documentation index, see [llms.txt](https://boinc-ai.gitbook.io/hub/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://boinc-ai.gitbook.io/hub/model-cards.md).
# Model Cards
## Model Cards
[New! Try our experimental Model Card Creator App](https://huggingface.co/spaces/huggingface/Model_Cards_Writing_Tool)
### What are Model Cards?
Model cards are files that accompany the models and provide handy information. Under the hood, model cards are simple Markdown files with additional metadata. Model cards are essential for discoverability, reproducibility, and sharing! You can find a model card as the `README.md` file in any model repo.
The model card should describe:
* the model
* its intended uses & potential limitations, including biases and ethical considerations as detailed in [Mitchell, 2018](https://arxiv.org/abs/1810.03993)
* the training params and experimental info (you can embed or link to an experiment tracking platform for reference)
* which datasets were used to train your model
* your evaluation results
The model card template is available [here](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/modelcard_template.md).
### Model card metadata
A model repo will render its `README.md` as a model card. To control how the Hub displays the card, you should create a YAML section in the README file to define some metadata. Start by adding three `---` at the top, then include all of the relevant metadata, and close the section with another group of `---` like the example below:
Copied
```
---
language:
- "List of ISO 639-1 code for your language"
- lang1
- lang2
thumbnail: "url to a thumbnail used in social sharing"
tags:
- tag1
- tag2
license: "any valid license identifier"
datasets:
- dataset1
- dataset2
metrics:
- metric1
- metric2
---
```
The metadata that you add to the model card enables certain interactions on the Hub. For example:
* Allow users to filter and discover models at [https://boincai.com/models](https://huggingface.co/models).
* If you choose a license using the keywords listed in the right column of [this table](https://huggingface.co/docs/hub/repositories-licenses), the license will be displayed on the model page.
* Adding datasets to the metadata will add a message reading `Datasets used to train:` to your model card and link the relevant datasets, if they’re available on the Hub.
Dataset, metric, and language identifiers are those listed on the [Datasets](https://huggingface.co/datasets), [Metrics](https://huggingface.co/metrics) and [Languages](https://huggingface.co/languages) pages and in the [`datasets`](https://github.com/huggingface/datasets) repository.
See the detailed model card metadata specification [here](https://github.com/huggingface/hub-docs/blob/main/modelcard.md?plain=1).
#### Specifying a library
You can also specify the supported libraries in the model card metadata section. Find more about our supported libraries [here](https://huggingface.co/docs/hub/models-libraries). The library can be specified with the following order of priority
1. Specifying `library_name` in the model card (recommended if your model is not a `transformers` model)
Copied
```
library_name: flair
```
2. Having a tag with the name of a library that is supported
Copied
```
tags:
- flair
```
If it’s not specified, the Hub will try to automatically detect the library type. Unless your model is from `transformers`, this approach is discouraged and repo creators should use the explicit `library_name` as much as possible.
1. By looking into the presence of files such as `*.nemo` or `*saved_model.pb*`, the Hub can determine if a model is from NeMo or Keras.
2. If nothing is detected and there is a `config.json` file, it’s assumed the library is `transformers`.
#### Evaluation Results
You can even specify your **model’s eval results** in a structured way, which will allow the Hub to parse, display, and even link them to Papers With Code leaderboards. See how to format this data [in the metadata spec](https://github.com/huggingface/hub-docs/blob/main/modelcard.md?plain=1).
Here is a partial example (omitting the eval results part):
Copied
```
---
language:
- ru
- en
tags:
- translation
license: apache-2.0
datasets:
- wmt19
metrics:
- bleu
- sacrebleu
---
```
If a model includes valid eval results, they will be displayed like this:

#### CO \ 2 \ Emissions
The model card is also a great place to show information about the CO2 impact of your model. Visit our [guide on tracking and reporting CO2 emissions](https://huggingface.co/docs/hub/model-cards-co2) to learn more.
#### Linking a Paper
If the model card includes a link to a paper on arXiv, the Hugging Face Hub will extract the arXiv ID and include it in the model tags with the format `arxiv:`. Clicking on the tag will let you:
* Visit the Paper page
* Filter for other models on the Hub that cite the same paper.
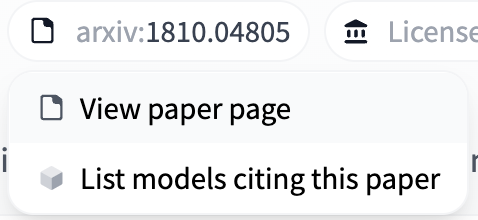
Read more about Paper pages [here](https://huggingface.co/docs/hub/paper-pages).
### FAQ
#### How are model tags determined?
Each model page lists all the model’s tags in the page header, below the model name. These are primarily computed from the model card metadata, although some are added automatically, as described in [Creating a Widget](https://huggingface.co/docs/hub/models-widgets#creating-a-widget).
#### Can I write LaTeX in my model card?
Yes! The Hub uses the [KaTeX](https://katex.org/) math typesetting library to render math formulas server-side before parsing the Markdown.
You have to use the following delimiters:
* `$$ ... $$` for display mode
* `\\(...\\)` for inline mode (no space between the slashes and the parenthesis).