# Sentiment Tuning
## Sentiment Tuning Examples
The notebooks and scripts in this examples show how to fine-tune a model with a sentiment classifier (such as `lvwerra/distilbert-imdb`).
Here’s an overview of the notebooks and scripts in the [trl repository](https://github.com/huggingface/trl/tree/main/examples):
| File | Description |
| --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | --------------------------------------------------------------------------------------------------------- |
| [`examples/scripts/ppo.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/ppo.py)[](https://colab.research.google.com/github/huggingface/trl/blob/main/examples/sentiment/notebooks/gpt2-sentiment.ipynb) | This script shows how to use the `PPOTrainer` to fine-tune a sentiment analysis model using IMDB dataset |
| [`examples/notebooks/gpt2-sentiment.ipynb`](https://github.com/huggingface/trl/tree/main/examples/notebooks/gpt2-sentiment.ipynb) | This notebook demonstrates how to reproduce the GPT2 imdb sentiment tuning example on a jupyter notebook. |
| [`examples/notebooks/gpt2-control.ipynb`](https://github.com/huggingface/trl/tree/main/examples/notebooks/gpt2-control.ipynb)[](https://colab.research.google.com/github/huggingface/trl/blob/main/examples/sentiment/notebooks/gpt2-sentiment-control.ipynb) | This notebook demonstrates how to reproduce the GPT2 sentiment control example on a jupyter notebook. |
### Usage
Copied
```
# 1. run directly
python examples/scripts/ppo.py
# 2. run via `accelerate` (recommended), enabling more features (e.g., multiple GPUs, deepspeed)
accelerate config # will prompt you to define the training configuration
accelerate launch examples/scripts/ppo.py # launches training
# 3. get help text and documentation
python examples/scripts/ppo.py --help
# 4. configure logging with wandb and, say, mini_batch_size=1 and gradient_accumulation_steps=16
python examples/scripts/ppo.py --ppo_config.log_with wandb --ppo_config.mini_batch_size 1 --ppo_config.gradient_accumulation_steps 16
```
Note: if you don’t want to log with `wandb` remove `log_with="wandb"` in the scripts/notebooks. You can also replace it with your favourite experiment tracker that’s [supported by `accelerate`](https://huggingface.co/docs/accelerate/usage_guides/tracking).
### Few notes on multi-GPU
To run in multi-GPU setup with DDP (distributed Data Parallel) change the `device_map` value to `device_map={"": Accelerator().process_index}` and make sure to run your script with `accelerate launch yourscript.py`. If you want to apply naive pipeline parallelism you can use `device_map="auto"`.
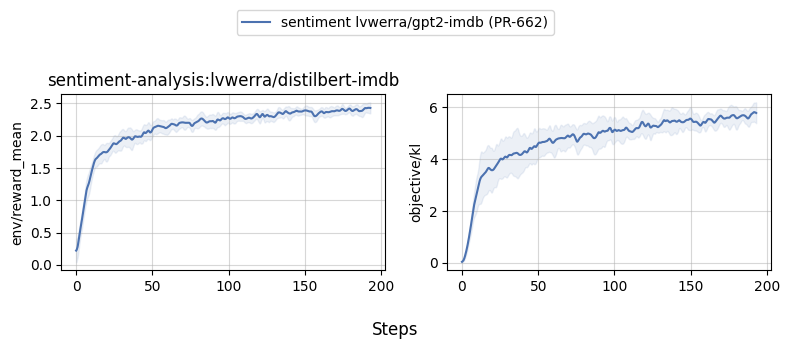
### Benchmarks
Below are some benchmark results for `examples/scripts/ppo.py`. To reproduce locally, please check out the `--command` arguments below.
Copied
```
python benchmark/benchmark.py \
--command "python examples/scripts/ppopy --ppo_config.log_with wandb" \
--num-seeds 5 \
--start-seed 1 \
--workers 10 \
--slurm-nodes 1 \
--slurm-gpus-per-task 1 \
--slurm-ntasks 1 \
--slurm-total-cpus 12 \
--slurm-template-path benchmark/trl.slurm_template
```
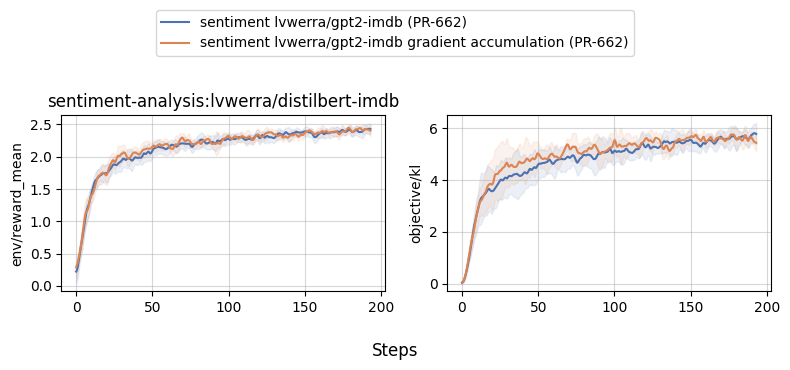
### With and without gradient accumulation
Copied
```
python benchmark/benchmark.py \
--command "python examples/scripts/ppo.py --ppo_config.exp_name sentiment_tuning_step_grad_accu --ppo_config.mini_batch_size 1 --ppo_config.gradient_accumulation_steps 128 --ppo_config.log_with wandb" \
--num-seeds 5 \
--start-seed 1 \
--workers 10 \
--slurm-nodes 1 \
--slurm-gpus-per-task 1 \
--slurm-ntasks 1 \
--slurm-total-cpus 12 \
--slurm-template-path benchmark/trl.slurm_template
```
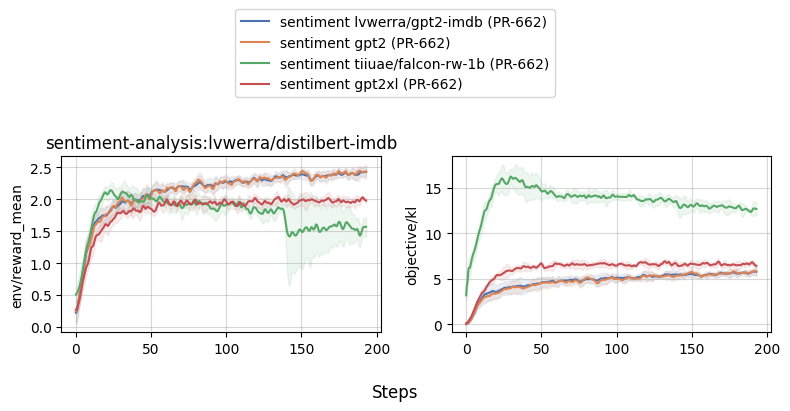
### Comparing different models (gpt2, gpt2-xl, falcon, llama2)
Copied
```
python benchmark/benchmark.py \
--command "python examples/scripts/ppo.py --ppo_config.exp_name sentiment_tuning_gpt2 --ppo_config.log_with wandb" \
--num-seeds 5 \
--start-seed 1 \
--workers 10 \
--slurm-nodes 1 \
--slurm-gpus-per-task 1 \
--slurm-ntasks 1 \
--slurm-total-cpus 12 \
--slurm-template-path benchmark/trl.slurm_template
python benchmark/benchmark.py \
--command "python examples/scripts/ppo.py --ppo_config.exp_name sentiment_tuning_gpt2xl_grad_accu --ppo_config.model_name gpt2-xl --ppo_config.mini_batch_size 16 --ppo_config.gradient_accumulation_steps 8 --ppo_config.log_with wandb" \
--num-seeds 5 \
--start-seed 1 \
--workers 10 \
--slurm-nodes 1 \
--slurm-gpus-per-task 1 \
--slurm-ntasks 1 \
--slurm-total-cpus 12 \
--slurm-template-path benchmark/trl.slurm_template
python benchmark/benchmark.py \
--command "python examples/scripts/ppo.py --ppo_config.exp_name sentiment_tuning_falcon_rw_1b --ppo_config.model_name tiiuae/falcon-rw-1b --ppo_config.log_with wandb" \
--num-seeds 5 \
--start-seed 1 \
--workers 10 \
--slurm-nodes 1 \
--slurm-gpus-per-task 1 \
--slurm-ntasks 1 \
--slurm-total-cpus 12 \
--slurm-template-path benchmark/trl.slurm_template
```
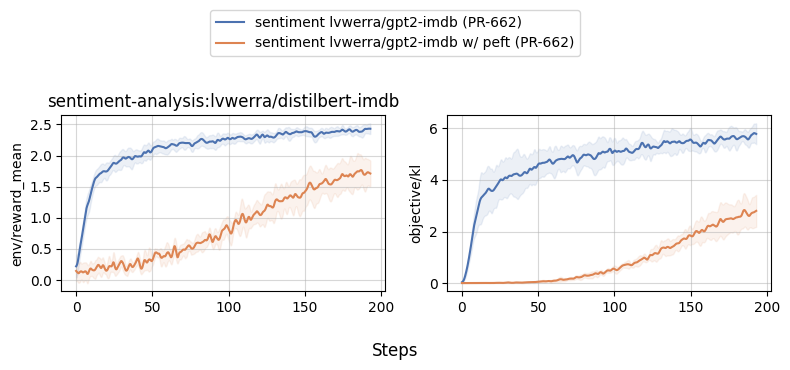
### With and without PEFT
Copied
```
python benchmark/benchmark.py \
--command "python examples/scripts/ppo.py --ppo_config.exp_name sentiment_tuning_peft --use_peft --ppo_config.log_with wandb" \
--num-seeds 5 \
--start-seed 1 \
--workers 10 \
--slurm-nodes 1 \
--slurm-gpus-per-task 1 \
--slurm-ntasks 1 \
--slurm-total-cpus 12 \
--slurm-template-path benchmark/trl.slurm_template
```
---
# Agent Instructions: Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter:
```
GET https://boinc-ai.gitbook.io/trl/examples/sentiment-tuning.md?ask=
```
The question should be specific, self-contained, and written in natural language.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.